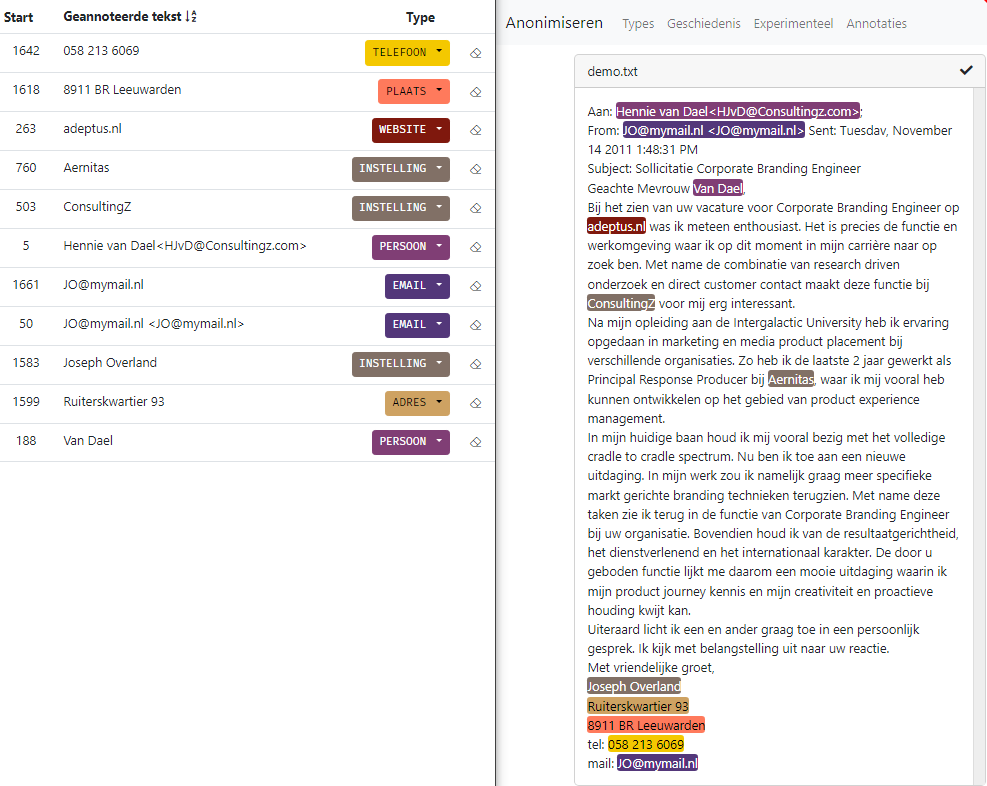
The purpose of named entity recognition is to detect a specific set of pre defined named elements in a text. Most commonly these are the names of persons companies and institutions.
In addition to these named elements, this demo also recognizes other data that can be traced back to a person, such as addresses, license plates, telephone numbers, etc.
Start the demo, and type or upload your document. The software will detect the entities and mark them in the document.
Good luck!
Background
We use a hybrid system to detect the named entities and other personally identifiable information. This system consists of the latest transformer-based language models, more traditional multi-feature neural networks and pattern-based recognition. For example, a simple pattern is sufficient to recognize a Dutch zip code: (four numbers, not starting with a 0 followed by a space and two capital letters). But recognizing and distinguishing personal and company names (the son of J. Jansen vs. J. Jansen and Sons) might require a more complex approach.
In addition, so-called black and white lists can be used. These are word lists that should always, resp. never be filtered out of the document.
Practical applications
The most obvious application for this technology is the anonymization of documents, for example to comply with the General Data Protection Regulation (GDPR). All data that can be traced back to a person can be replaced by a category designation. “Dear Mrs. Jansen” then becomes “Dear [PERSON]”. In many cases it is more readable if the role of the entity can be included. In this case, the above example could become “Dear [CUSTOMER]”. With our software we can achieve this by combining named entity recognition with a classification module that assigns the available roles to the detected entities.
A second practical application is in the field of data extraction. This involves finding specific data types in natural language and transforming them into structured data. This structured data can then be stored in a database to be used, for example, for quick analysis. The structured data can also be used as an index for the original documents to quickly find relevant documents.