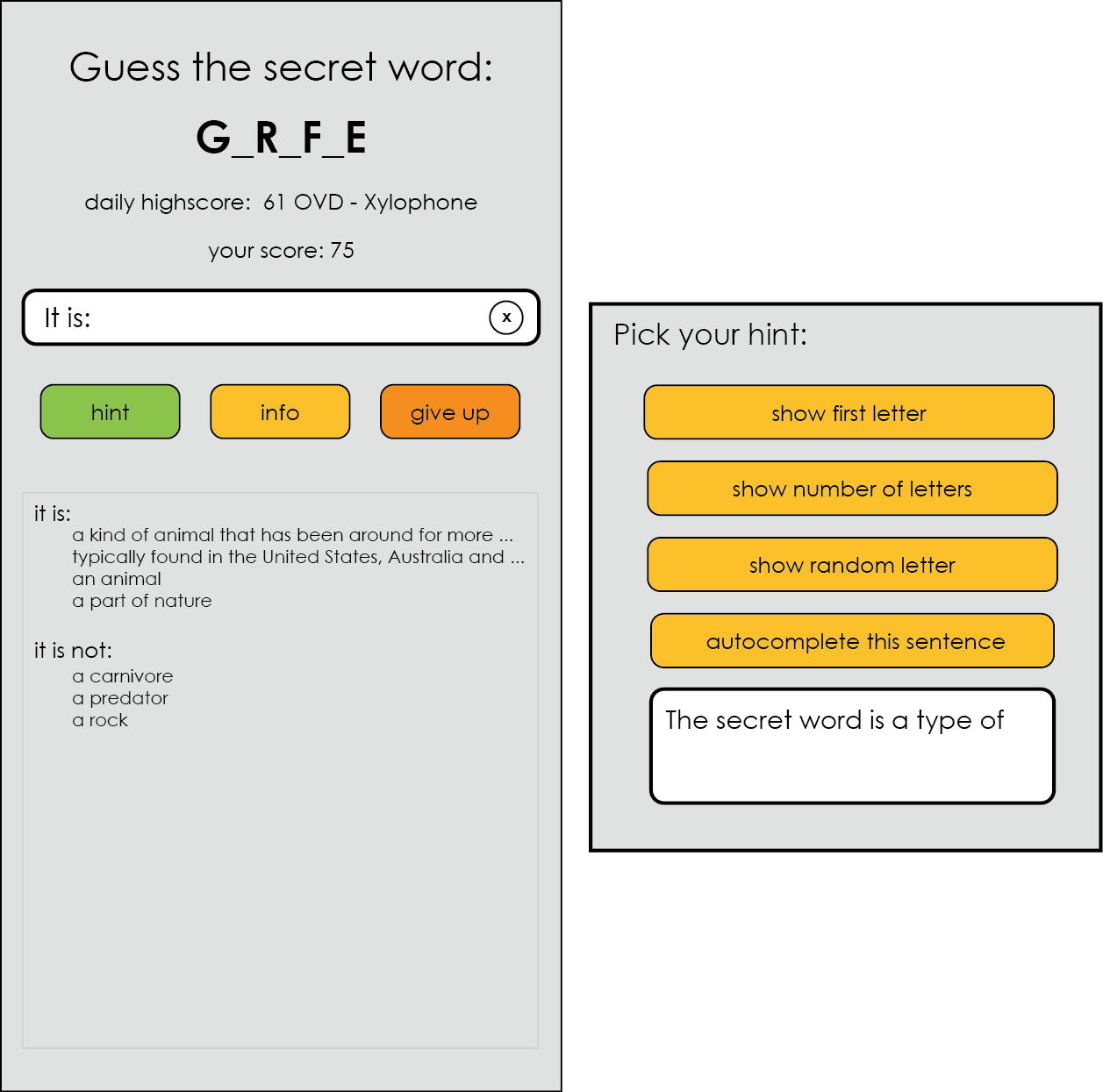
Semantic classification is al about assigning the correct meaning to words. The extent to which modern language technology succeeds in this case can, in our opinion, be nicely illustrated by the game “Guess the word”.
The computer chooses a random “secret word” and your job is to try to guess what it was by asking questions. The computer may answer only Yes or No.
Of course, the computer’s answer is only reliable if it has correctly “understood” both the secret word and your question. So it’s wise not to trust all the answers right away…
Start the demo and beat the high score.
Good luck!
Background
Several modern transformer based language models were used in the realization of this demo. A roBERTa NLI model is used for assessing the questions, i.e. the actual classification. For example, if you ask “Is it a vehicle”? then the classification score follows from whether the sentences “I am [the secret word]” entails “I am a vehicle”.
No explicit taxonomies such as dictionaries or other structured semantics were used in the development of the model. All knowledge about the language arose on the basis of statistical analyses about the extent to which words occur more or less often in the same context. This often results in remarkable associations. For example, the word “remote control” is more related to the word “father” than “mother”.
Practical applications
Very powerful applications can be made on the basis of these language models by “fine-tuning” the model. This is an additional training step where labeled samples are provided. The number of these examples often does not have to be large because the basic model (as used in this demo) already “knows” the most common concepts.
A few years ago thousands of manually labeled examples were often not sufficient to train a good classifier, but now often a few dozen per category will often suffice. This leads to semantic classifiers now being used for applications that used to be totally unfeasible. As a result, very powerful applications can now be quickly developed to support any process where documents are processed. For example, consider routing correspondence based on content or urgency or automatically marking or summarizing critical passages.