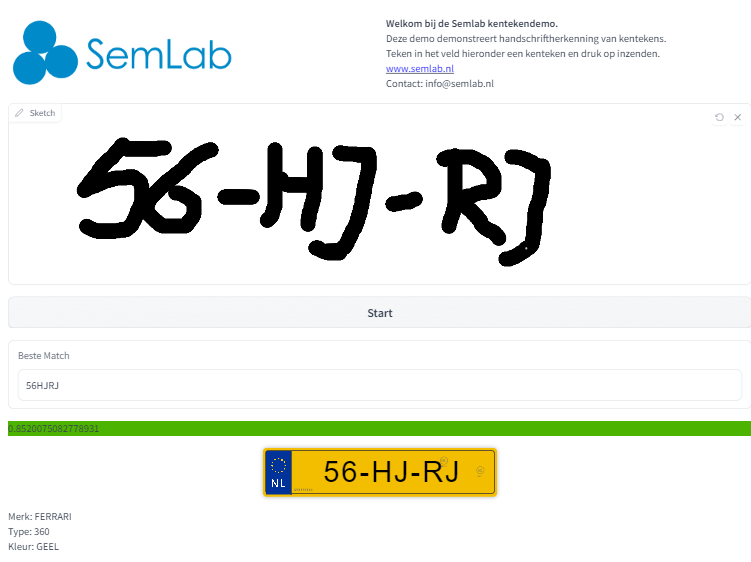
Met de nieuwe taalmodellen is het mogelijk om veel nauwkeuriger handgeschreven teksten te ontcijferen dan voorheen. In onze demo gebruiken we dit om handgeschreven kentekens te herkennen.
Start de demo, schrijf met de cursor een geldig kenteken in het tekenveld en druk op de “start” knop.
Uw geschreven tekst wordt nu automatisch ingelezen en vertaald naar de zes karakters op een Nederlands kenteken. Met dit kenteken wordt vervolgens wat aanvullende informatie opgehaald bij de RDW.
Veel succes!
Achtergrond
Het model wat bij deze demo gebruikt wordt is gebaseerd op het TrOCR model wat is ontwikkeld door onderzoekers bij Microsoft. dit model bestaat uit een vision transformer in combinatie met een Roberta model om de kenteken tekst te coderen. De image transformer splitst het plaatje met de handgeschreven tekst in een raster van blokken die als input dienen voor de transformer. Verder gebruikt dit model het self-attention mechanisme net als de tekst gebaseerde modellen die elders op deze demo site getoond worden.
Dit model is getraind op een corpus van miljoenen automatisch gegenereerde plaatje en specifiek voor de taak van kentekenherkenning verder gefinetuned op enkele tienduizenden synthetische kentekenplaatjes. Om het model nog robuuster te maken is deze dataset uitgebreid met behulp van ‘data augmentation’. Hierbij worden de originele plaatjes op verschillende manieren vervormd om overfitten van tijdens het trainen te voorkomen.
Toepassingen
Praktische toepassing van dit soort modellen liggen uiteraard op het gebied van het herkennen van teksten in plaatjes. Hierbij kan het om handgeschreven teksten gaan, maar dit hoeft niet. Ook ons model is prima instaat om gedrukte teksten correct te ontcijferen. Dit is bijvoorbeeld handig bij het automatisch verwerken van ingevulde formulieren. De software van deze demo van het herkennen van handgeschreven kentekens wordt bijvoorbeeld gebruikt bij het automatisch verwerken van ingevulde autoschade-formulieren.