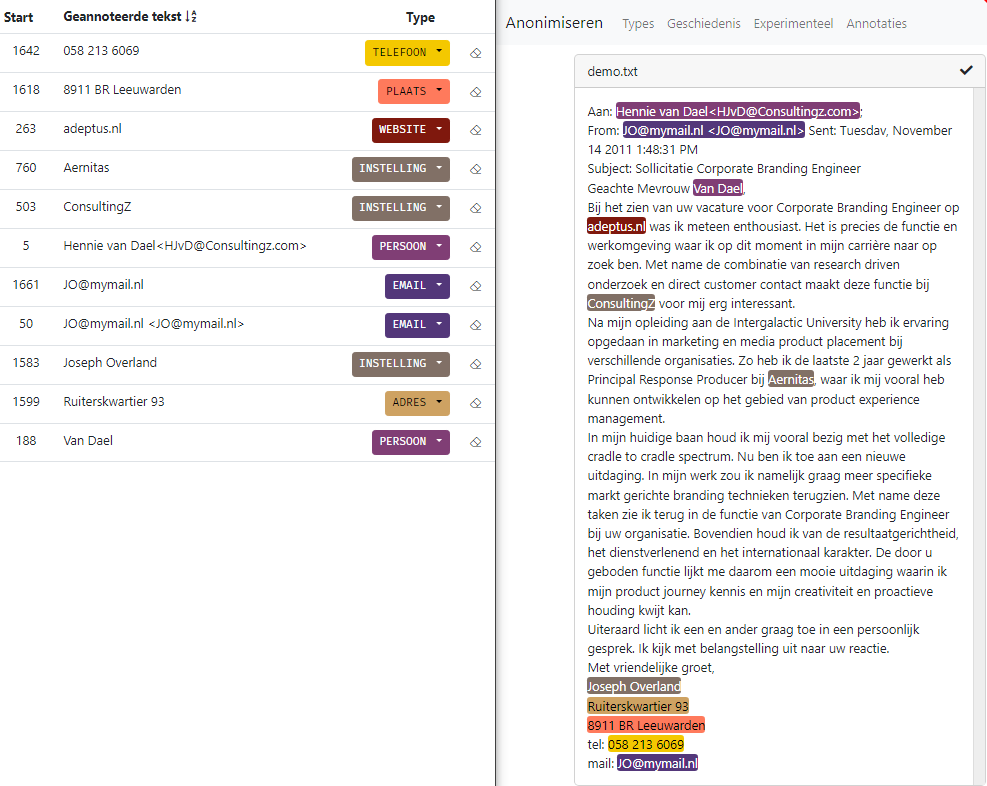
De correcte, maar niet erg gebruikelijke Nederlandse vertaling van named entity recognition is “herkenning van benoemde elementen”. Dit zijn onder meer namen van personen, bedrijven en instellingen.
Deze demo herkent naast “benoemde elementen” ook andere tot een persoon herleidbare gegevens zoals bijvoorbeeld adressen, kentekens, telefoonnummers etc.
Start de demo, en type of upload uw document en de software zal hierin de gegevens opzoeken en in het document markeren.
Veel succes!
Achtergrond
Voor het vinden van named entities en andere tot een persoon herleidbare gegevens gebruiken wij een hybride systeem bestaande uit de nieuwste transformer gebaseerde taalmodellen, meer traditionele multi-feature neurale netwerken en patroon gebaseerde herkenning. Zo is bijvoorbeeld voor het herkennen van een postcode een eenvoudig patroon voldoende: (vier cijfers, niet beginnend met een 0 gevolgd door eventueel een spatie en twee hoofdletters). Maar voor het herkennen en onderscheiden van persoons en bedrijfsnamen (de zoon van J. Jansen vs. J. Jansen en zn.) is een meer complexe aanpak nodig.
Daarnaast kan er uiteraard ook gebruik gemaakt worden van zogenaamde zwarte en witte lijsten (black-lists en white-lists). Dit zijn woordenlijsten die altijd, resp. nooit uit het document gefilterd moeten worden.
Toepassingen
De meest voor de hand liggende toepassing voor deze technologie is het zogenaamd anonimiseren van documenten bijvoorbeeld om te voldoen aan de Algemene verordening gegevensbescherming (AVG). Hierbij worden alle tot de persoon herleidbare gegevens vervangen door een categorie aanduiding. “Beste mevrouw Jansen” wordt dan “Beste [PERSOON]” . In veel gevallen is het prettiger voor de leesbaarheid als de rol van de entiteit kan worden meegegeven. In dit geval zou het bovenstaande voorbeeld “Beste [KLANT]” kunnen worden. Met onze software kunnen we dit realiseren door de named entity recognition te combineren met een classificatie module die de beschikbare rollen toekend aan de gevonden entiteiten.
Een tweede praktische toepassing ligt op het gebied van de data extractie. Hierbij gaat het om het vinden van specifieke datatypes in natuurlijke taal om deze te vertalen naar gestructureerde data. Deze gestructureerde data kan dan worden opgeslagen in een database om bijvoorbeeld gebruikt te worden voor snelle analyse. Ook kan de gestructureerde data gebruikt worden als index voor de oorspronkelijke documenten om snel relevante documenten op te zoeken.