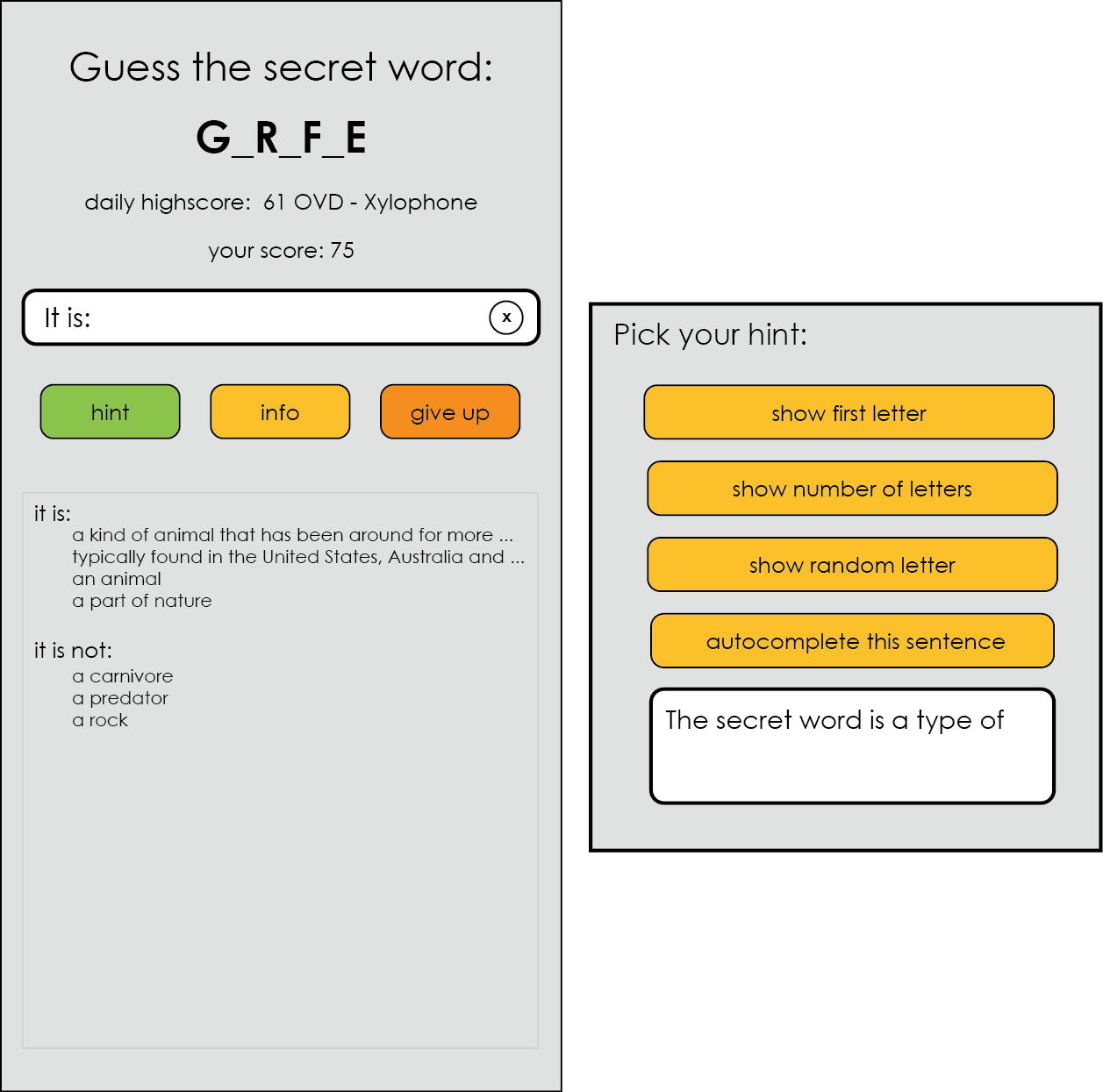
Bij semantische classificatie moet aan woorden de correcte betekenis worden toegekend. De mate waarin moderne taaltechnologie hierin slaagt kan naar ons idee fraai geïllustreerd worden door het spel “Raad het woord”.
De computer kiest een random “geheim woord” en u mag hier naar raden door vragen te stellen. De computer mag alleen met Ja of Nee antwoord geven.
Uiteraard is het antwoord van de computer alleen betrouwbaar als hij zowel het geheime woord als uw vraag goed heeft “begrepen”. Het is dus verstandig om niet alle antwoorden meteen te vertrouwen…
Start de demo en versla de highscore.
Veel succes!
Achtergrond
Bij de realisatie van deze demo zijn meerdere moderne transformer gebaseerde taalmodellen gebruikt. Voor het beoordelen van de vragen, dus het daadwerkelijk classificeren, wordt een roBERTa NLI model gebruikt . Als u bijvoorbeeld vraagt “Is het een voertuig”? dan volgt de classificatie score uit de vraag of de zinnen “Ik ben [het geheime woord]” en “Ik ben een voertuig” elkaar impliceren.
Bij de totstandkoming van het model zijn geen expliciete taxonomieën zoals woordenboeken of andere gestructureerde semantiek gebruikt. Alle kennis over de taal is ontstaan op basis van statistische analyses over de mate waarin woorden meer of minder vaak in de zelfde context voorkomen. Hierdoor kunnen voor de mens merkwaardige associaties ontstaan. Zo is bijvoorbeeld het woord “afstandsbediening” meer gerelateerd aan het woord “vader” dan “moeder”.
Toepassingen
Op basis van deze taalmodellen kunnen ontzettend krachtige toepassingen worden gemaakt door het model te “finetunen”. Dit is een extra trainingstap waarbij gelabelde voorbeelden worden aangeboden. Het aantal van deze voorbeelden hoeft vaak niet groot te zijn omdat het basismodel (zoals in deze demo werd gebruikt) al de meest voorkomende begrippen “kent”.
Waar in het verleden duizenden handmatig gelabelde voorbeelden vaak niet voldoende waren om een goede classifier te trainen kan nu vaak volstaan worden met enkele tientallen per categorie. Hierdoor kunnen nu semantische classifiers worden ingezet voor toepassingen waar dit voorheen onhaalbaar was. Hierdoor kunnen nu snel zeer krachtige applicaties worden ontwikkeld ter ondersteuning van ieder proces waar documenten worden verwerkt. Denk bijvoorbeeld aan het routeren van correspondentie of het automatisch markeren of samenvatten van kritische passages.