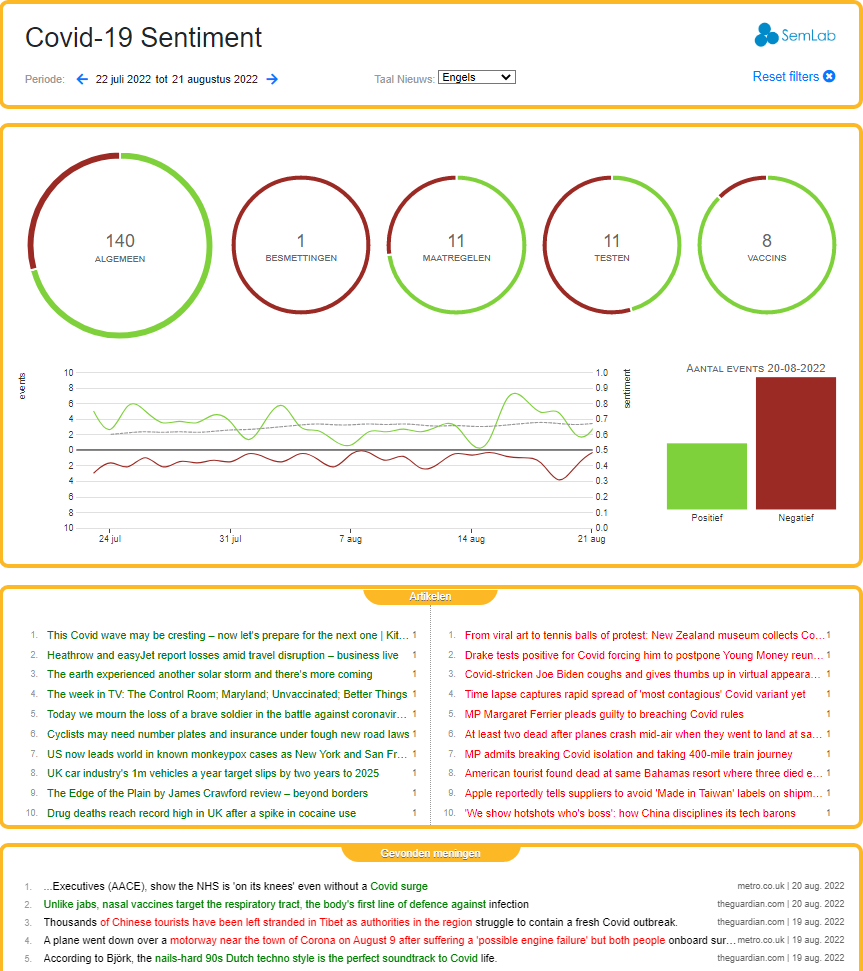
Deze applicatie houdt continu vele nieuwssites in de gaten en verzamelt hiervan de berichten die betrekking hebben op COVID-19. In deze berichten wordt vervolgens het sentiment gedetecteerd. Dit sentiment wordt tenslotte weergegeven in een grafische interface waardoor snel een indruk van het huidige sentiment over dit onderwerp wordt verkregen.
In de applicatie kan gekozen worden voor nieuwssites in verschillende talen. Ook kan worden doorgeklikt naar de zinnen en berichten waarin het sentiment werd gevonden.
Start de demo, en klik op de verschillende nieuwsbronnen, berichten of aspecten van het COVID-19 nieuws om te filteren en kijk hoe dit het sentiment beïnvloed.
Veel succes!
Achtergrond
De nieuwsberichten worden via RSS feeds van de verschillende dagbladen opgehaald. Vervolgens worden de berichten gefilterd op basis van corona/covid gerelateerde termen die worden bijgehouden in een ontologie. Het sentiment wordt toegekend door een speciaal hiervoor getrainde roBERTa classifier. Hierbij wordt, naast een algemeen sentiment, onderscheid gemaakt tussen vier verschillende aspecten van de pandemie: besmettingen, maatregelen, testen en vaccinaties.
Om dit onderscheid te kunnen maken is de classifier is getraind voor Natural Language Inference. Dit houdt in dat hiermee de zogenaamde “entailment” tussen twee teksten kan worden gedetecteerd. Dit is van belang omdat in een enkele zin verschillende sentimenten tegelijk kunnen worden uitgesproken.
Bijvoorbeeld de zin: “Ondanks de afgenomen vaccinatie bereidheid is het aantal besmettingen gedaald“: Deze zin drukt een negatief sentiment uit voor het aspect vaccinaties maar voor het aspect besmettingen is het sentiment positief.
Om ook anderstalige nieuwsberichten te kunnen verwerken maakt dit systeem gebruik van “machine translation”. Hiermee worden alle berichten eerst vertaald naar Engels. Hierdoor kan dit systeem volstaan met maar één sentiment classifier voor alle verschillende talen.
Toepassingen
Dit media sentiment detectie systeem is volledig generiek van opzet en kan dus zonder aanpassingen aan de systematiek gebruikt worden voor alle denkbare onderwerpen. Zo hebben wij bijvoorbeeld dezelfde opzet gebruikt om het sentiment rond alle in Nederland leverbare automobiel merken en types te monitoren. Anders dan traditionele sentiment detectie systemen kunnen wij tegelijkertijd het sentiment over verschillende aspecten van het onderwerp onderscheiden. Bij de auto’s is dit het sentiment met betrekking tot het uiterlijk, rijgedrag, prijs, verbruik, uitrusting, comfort en veiligheid.
Met het Semlab media sentiment detectie systeem kan dus in real-time het sentiment in vele talen voor een vrij te kiezen onderwerp worden gedetecteerd. Bovendien kan simultaan het sentiment van verschillende aspecten van dit onderwerp worden onderscheiden. In tegenstelling tot andere leveranciers leveren wij geen “black box”. Ons systeem is volledig transparant. Het gerapporteerde sentiment kan altijd gerelateerd worden aan het bericht met daarin de passage waarin dit sentiment werd uitgesproken. En deze berichten kunnen direct ter controle worden weergegeven.